
Det har varit ganska glest mellan uppdateringarna här på bloggen ett tag, och jag misstänker att åtminstone en del av min trogna läsarkrets[1] börjat frukta att jag fallit offer för något slags östasiatiskt virus. Ett sådant gjorde ju entre för dryga tiotalet år sedan, och det är detta som jag nu fallit pladask för. Men nej, jag pratar inte om Covid-19, eller någon annan covid-släkting — jag pratar om Sudoku.
Det började lite lätt med att jag någon gång under förra vintern upptäckte att The Guardian på helgerna publicerade något som de kallade »killer sudoku». Detta fenomen var åtminstone relativt nytt för mig, och jag fann snart att även om de oftast var någon nivå svårare än vanliga vanilj-sudokus, så kunde de också bjuda på mer intressanta logiska slutledningar.
Men sjukdomen bröt inte ut på allvar förrän jag i just The Guardian stötte på en artikel om ett märkligt youtube-fenomen, en kanal vid namn Cracking the Cryptic, där två distingerade engelsmän löser sudokus och andra logiska problem av varierande svårighetsgrad, från dunderknepiga till snudd på omöjliga, i realtid[2]. Den video som länkades till i artikeln behandlar en så kallad »miracle sudoku», som består av en nästan tom sudoku, där bara två(!) siffror angetts, och tre extra villkor — (1) två likadana siffror får inte placeras ett springarsteg ifrån varandra; (2) två likadana siffror får inte placeras ett kungssteg[3] ifrån varandra; och (3) två konsekutiva siffror får inte placeras i ortogonalt angränsande rutor[4]. Så här ser miraklet ut:
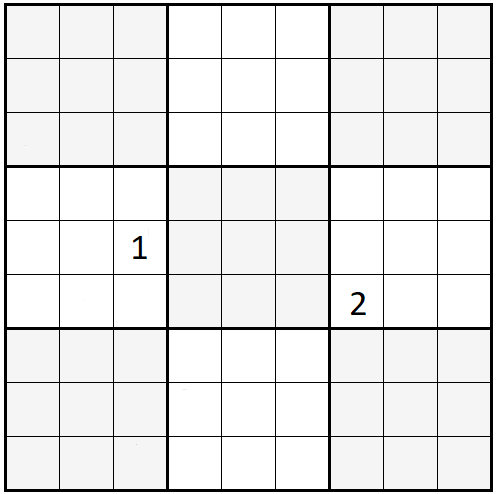
Erkänn att det är svårt att tro både att det finns en unik lösning, och att det i så fall går att hitta den utan datorhjälp. Men det är faktiskt inte alls så knepigt, visade det sig när man kom igång; den enda »krisen» kommer när man placerat in alla ettor och tvåor som går att placera, och måste börja placera treor — där måste man endera vara intelligent, som Simon Anthony i en video som för tillfället setts sådär 1,5 miljoner(!) gånger, eller ihärdig, som under-över-eller-var-jag-nu-är-tecknad[5].
Riktigt allvarlig blev dock inte sjukdomsbilden förrän min nyfikenhet drev mig att googla efter en sajt som CtC, som Cracking the Cryptic brukar förkortas, hämtat ett flertal av sina mest intressanta objekt från — Logic Masters Germany. Särskilt deras lista med sudokus, med variationer av alla möjliga slag fångade mig. Jag inser naturligtvis att jag inte borde sprida sjukdomen så här lättvindigt, men här kommer några av de problem som jag fastnat för. De prövas, naturligtvis, på egen risk — you have been warned…
- Fyra små rätter. Det här är förmodligen det enklaste problemet i den här listan; det består av fyra 6*6 sudokus med lite olika interna varianter, som länkas samman av en summa där (oftast) två av de ingående delproblemen ger bidrag. Lite matematiska kunskaper skadar inte, som till exempel att triangeltalen för 5 och 6 är 15 respektive 21.
- 144, men inte 35. Det här är likaledes förmodligen det svåraste av de här uppräknade problemen; om man inte har en matematisk överblick måste man ta hjälp av papper och penna, Notepad eller, som i mitt fall, Excel[6]. Kompositören har delat in de 81 sudoku-rutorna i sexton fem-rutiga områden (så kallade pentominos) och en överbliven ruta, samt meddelar att alla utom en har två egenskaper, förutom den »vanliga» att inga dublettsiffror är tillåtna: (1) produkten av de fem talen i pentominon är jämnt delbar med 144, och (2) produkten är inte delbar med 35. Om du till äventyrs skulle fundera på att skapa ett problem där alla 16 pentominorna följer denna enkla regel, så kommer du snart att upptäcka att den elaka verkligheten sätter upp vissa hinder i din väg. Meddela mig gärna om du lyckas, men jag hoppas du ursäktar om jag tar ett eller annat andetag under tiden.
- Oss fyrkanter emellan. Ett annat problem med en utpräglat matematisk grundidé (enligt uppgift är kompositören en amerikansk matematiklärare). Här står kvadrater för de huvudsakliga ledtrådarna, kompletterade av några diagonalsummor som av någon anledning går under namnet »little killers».
- En schacksudoku. Att matematik och sudoku hör samman är väl ganska naturligt, men det finns faktiskt en hel del sudokus med schackinslag också, inte bara de anti-regler som var viktiga komponenter i miraklet ovan. Det här är en av dem; nio kungar, representerade av ettor, måste skyddas från schackar av torn, löpare och springare (2,3 och 4). En intressant idé, som fått en genomgång på CtC.
- En genial idé. Ett av de första problem jag löste på sajten, och jag prickade ett mästerverk; det är inte bara jag som tycker så — med 35 lösare har den fortfarande en ranking på 100%, en högre uppskattning är svår att få. Idén är lika enkel som genial; ett antal »mördarlådor», där summan av de två talen är exakt tio, några »termometrar, som indikerar siffror i en stigande sekvens räknat från »kvicksilverkulan», och det antispringarvillkor vi bekantade oss med i mirakelsudokun. Problemet får mig att tänka på Göran (Forslund); det här är ett problem han skulle gillat, eller till och med kunnat komponera. (Även detta problem har lösts av CtC.)
- En golvläggarsudoku.Till slut ett problem som i skrivande stund enbart har en (officiell) lösare, och det här är ett försök att ändra på den saken. Att det bara är en lösare betyder emellertid inte att det är ett oerhört svårt problem; snarare är det en indikation på att reglerna var ganska oklart formulerade från början. Det som gjorde att jag kunde lösa den var att jag skrev en dold kommentar (dvs en kommentar som bara kommentatorn, författaren och de som löst problemet kan se) där jag förklarade mina (som det skulle visa sig felaktiga) tolkningar av reglerna, och varför jag såg mig tvungen att ge upp. Författaren förtydligade då reglerna, vilket gjorde att jag ganska raskt kunde finna lösningen. Så gör gärna ett försök att knäcka nöten; om inte annat för att det inte är varje dag som kvadratroten ur 20 innehar en viktig roll i en sudoku.
Jag hoppas att du kunnat njuta av någon eller några av dessa logiska läckerheter, utan att bli smittad av den åkomma som jag råkat utför. Tyvärr använder jag inte munskydd, men i mitt nuvarande skäggiga tillstånd lär det inte ha gjort särskilt stor nytta i alla fall.
![]()
And now for something not completely different…
För något år sedan fick jag ett så kallat ryck, och bestämde mig för att försöka lära mig något om logikprogrammering. Valet föll på Prolog eftersom jag relativt nyligen hittat en bok om detta språk på ett antikvariat[7]; någonstans i bakhuvudet fanns säkert tanken att det borde relativt lätt gå att lösa sudokus med ett sådant språk. Jag laddade också ned GNU-Prolog, och började läsa, googla och testa.
Innan jag fortsätter bör jag komma med en brasklapp av ansenliga mått; mina kunskaper i Prolog är forfarande på nybörjarnivå, och alla uppgifter om språket jag kommer att uttrycka och de programexempel jag visar bör betraktas som just synpunkter från en nybörjare i logikprogrammering, men med relativt stor erfarenhet av »traditionell» programmering.
Jag började med klassiska problem av den typ som Göran tog upp i sin problembok, och vars lösning jag avslöjade i mina errata till Görans bok. Så här ser mitt program ut:
solvetrav :- Trav = [[1,_,_],[2,_,_],[3,_,_]], members([[_,ptro,_],[_,gnagg,_],[_,galopp,_]],Trav), members([[_,_,nisse],[_,_,janne],[_,_,sven]],Trav), member([3,gnagg,_],Trav), member([2,_,sven],Trav), nonmember([1,_,janne],Trav), nonmember([_,galopp,nisse],Trav), write(Trav), nl, fail.
Den första raden bestämmer att lösningen (»Trav») ska vara en lista bestående av tre listor, där varje lista består av tre uppgifter; tillsammans med de två övriga raderna i det första blocket ser man att de är placeringen, hästnamnet och ägaren i den ordningen (variabeln »_» är speciell, och uttolkas »här kan du stoppa in vad du vill; jag bryr mig inte».)
Det följande kodblocket anger de uppgifter man känner till om loppet — Gnägg kom trea (det var, har jag för mig, den häst som bröt benet), Svens häst kom tvåa, Jannes häst vann inte och Nisses häst hette inte Galopp. Kommatecknen mellan uppgifterna fungerar som logiska »och»; så länge som det går att konstruera en lösning fortsätter programmet, annars backar det något eller några steg för att pröva något annat.
Det sista blocket är ett standardtrick för att finna alla möjliga lösningar; skriv ut lösningen och en ny rad, samt låtsas att det inte var den här lösningen man sökte. Jag bör kanske påpeka att »members» och »nonmember» inte är standardrutiner i Prolog, utan sådant som jag hittat på nätet, så programmet som sådant går inte att köra direkt utan att man lägger till de komponenterna.
![]()
Innan jag fortsätter känner jag mig förpliktigad att försvara mig, eller åtminstone förklara mig. När allt kommer omkring ställde jag ju i början av 90-talet upp tre enkla regler för användandet av rekursion:
- Använd inte rekursion.
- Använd inte rekursion!!
- Använd rekursion då, om du absolut måste, men skyll inte på mig om det leder till kärnvapenkrig, pandemier eller att himlen trillar ned över ditt huvud.
Åkej, jag kanske inte hotade med pandemier på den tiden, men jag hoppas den allmänna avogheten mot rekursion som dessa rader är avsedda att förmedla framgår tydligt. Vad jag eventuellt inte berättade för alla som fick ta del av mina rekursionstips var den bakomliggande historien.
Under min tid som programmeringssupport vid NSC fick jag en gång ett mejl, där en person frågade varför ett visst program bara var 2-3 ggr snabbare på Crayen än på användarens arbetsstation. Programmet i fråga visade sig beräkna (om jag minns rätt) — det 40:e fibonaccitalet, uträknat med den rekursiva formel man ibland kan hitta i mindre nogräknade läromedel. Jag är fast motståndare till dödsstraff, men skulle jag tvingas ange ett brott som förtjänar ett sådant straff bör sagda läromedels författare snarast vidta åtgärder som att byta namn och skaffa lösskägg[8]. Tiotalet år senare såg jag en IT-journalist skriva något i stil med att hen testade en dator med en »tung beräkning», vilket visade sig vara en fibonacciberäkning av liknande slag.
Jag gissar att jag skulle kunna räkna ut det 40:e fibonaccitalet med papper, penna och, säg, en halvtimmes arbete; och jag försäkrar att all aritmetik jag kan utföra på en halvtimme ska en dator värd namnet klara av att utföra på mindre än en mikrosekund. Med andra ord, de 118[9] CPU-sekunder som vår Cray X-MP använde för att beräkna det 40:e fibonaccitalet hade kunnat användas till bättre ting. Som en jämförelse tog en standardkörning av mitt program för att beräkna en viss typ av spektrum för en mellanstor molekyl (ca 40-50 atomer) ca 90 CPU-sekunder på samma maskin.
Numera är jag, som kanske framgått, inte fullt lika rabiat motståndare till rekursion, och har till och med börjat använda det här och var själv, när ingen ser på. Jag har därför modifierat den tredje punkten ovan till »Det är tillåtet att använda rekursion, om du först skaffat dig 20 års erfarenhet av ett riktigt programmeringsspråk[10][11].
Det finns ett grundläggande problem här, vars existens jag för tillfället inte hittar någon författare som vågar erkänna rakt av. Det bästa jag kan erbjuda är ett citat ur Concepts of programming languages (3. ed) av Robert W. Sebesta: »One of the essential characteristics of logic programming languages is their semantics, which is called declarative semantics. The basic concept of this semantics is that there is a simple way to determine the meaning of each statement, and it does not depend on how the statement might be used to solve a problem.» Låt mig formulera om det så som jag har förstått det: »Prolog och språk av liknande typ gör att användaren bara behöver specifiera alla kända data, hur lösningen sedan ska hittas bestäms av programmet vid körningen.» Min åsikt om detta är att det uttrycker ett slags önskedröm, vars förverkligande möjligen ligger i en (avlägsen?) framtid, och att de program som för tillfället existerar kan i bästa fall ses som leksaker, som är bra på att lösa vissa typer av problem, men kräver ingående kännedom om hur programmet fungerar för att lösa dessa problem. Och detta förklarar/försvarar mitt intresse i Prolog — som pensionär är jag fri att välja mina leksaker som jag vill! SDS[12], OHS[13] och QED.
![]()
Du är inte övertygad om att Prolog är usel på att hitta lösningsmetod själv? Eller tror inte att man som programmerare kan hjälpa till? Låt mig då visa ett exempel; ganska extremt, det medges, men samtidigt hoppas jag det är illustrativt.
Problemet jag tänkte ta upp är följande, från 536 Puzzles & Curious Problems av en av alla tiders största problemmakare — Henry Dudeney. Detta är närmare bestämt nummer 393 i boken:
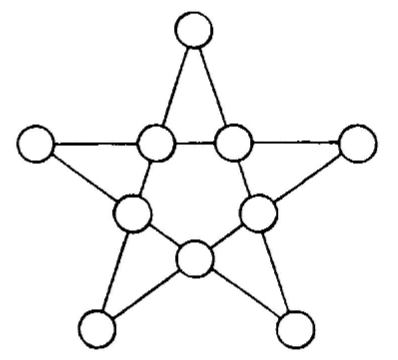
There is something very fascinating about star puzzles. I give an example, taking the case of the simple five-pointed star. It is required to place a different number in every circle so that the four circles in a line shall add up to 24 in all the five directions. No solution is possible with ten consecutive numbers, but you can use any whole number you like.
Och utan några alltför stora krumbukter, här kommer lösningsförslag 1, den stendumma varianten:
solvefivestar :- Numbers = [N0,N1,N2,N3,N4,N5,N6,N7,N8,N9], integerlist(1,18,Tal), member(N0,Tal), member(N1,Tal), member(N2,Tal), member(N3,Tal), member(N4,Tal), member(N5,Tal), member(N6,Tal), member(N7,Tal), member(N8,Tal), member(N9,Tal), uniquelist(Numbers), (N0+N5+N6+N2 =:= 24), (N0+N9+N8+N3 =:= 24), (N1+N5+N9+N4 =:= 24), (N1+N6+N7+N3 =:= 24), (N2+N7+N8+N4 =:= 24), write(Numbers), nl, fail.
»integerlist» och »uniquelist» är två enkla komponenter som jag skrev för att dels skapa en lista med heltal som kunde bli aktuella (som synes räknade jag bara med positiva heltal), samt att kontrollera att det inte fanns dubletter i lösningslistan. 18 valde jag efter en snabb huvudräkning, som sa att 18+1+2+3 = 24, så något tal större än 18 kunde med säkerhet inte komma ifråga i lösningmängden.
Här har jag bara deklarerat vilka tal som kan vara aktuella, och vilka relationer som gäller mellan dem, utan några krusiduller. När jag körde programmet hände dock ingenting. Jag vill minnas att jag bröt efter så där en och en halv timma, och då hade programmet inte ens hittat en enda lösning. Jag kan visserligen utesluta möjligheten av att den fortfarande skulle ha letat om jag inte tryckt på ctrl-c, men det beror mer på att den dator den körde på säckade ihop för gott för en månad sedan.
Skam den som ger sig. Jag misstänkte naturligtvis att den algoritm som programmet använde i princip kunde betecknas som 10 for-loopar inuti varandra, och det kunde ju förklara varför den tog så lång tid på sig. Ett rimligt försök att snabba upp beräkningen borde då vara att presentera de begränsande villkoren så snart som möjligt. Denna tanke ledde till detta detta program, med lite mänsklig hjälp:
solvefivestar(Const) :- Numbers = [N0,N1,N2,N3,N4,N5,N6,N7,N8,N9], integerlist(1,18,Tal), member(N0,Tal), member(N2,Tal), member(N5,Tal), (N6 is Const -(N0+N2+N5)), member(N6,Tal), member(N3,Tal), member(N8,Tal), (N9 is Const -(N0+N3+N8)), member(N9,Tal), member(N1,Tal), (N4 is Const -(N1+N5+N9)), member(N4,Tal), (N7 is Const -(N1+N6+N3)), member(N7,Tal), uniquelist(Numbers), (N2+N7+N8+N4 =:= Const), write(Numbers), nl, fail.
Som synes är detta program inte lika enkelt att förstå som förra försöket; i stället för ett block med deklarationer och ett med relationer, så har jag den här gången introducerat relationerna så tidigt som möjligt för att begränsa de nödvändiga looparna. Och resultatet är över förväntan; på min gamla dator, den som säckade ihop, spottade den ut ett par skärmsidor lösningar på lite drygt sex sekunder, och ersättaren, den som jag använder nu, tar bara 4.5 sekunder på sig. En remakaber[14] skillnad, eller hur?
Nu är jag naturligtvis inte den förste som noterat att Prolog inte är särskilt bra på den här typen av problem. Jag hittade en artikel på nätet som beklagade sig över att man fortfarande lärde ut ”is” och aritmetisk likhet (=:=), när det fanns så mycket bättre möjligheter (om jag minns rätt kallade författaren det hela för constraint programming over finite domains, vilket jag inte vågar mig på att försöka översätta). Idéerna i artikeln resulterade i följande program:
solvefivestarcp(Const) :- Numbers = [N0,N1,N2,N3,N4,N5,N6,N7,N8,N9], fd_domain(Numbers,1,18), fd_all_different(Numbers), N0+N5+N6+N2 #= Const, N0+N9+N8+N3 #= Const, N1+N5+N9+N4 #= Const, N1+N6+N7+N3 #= Const, N2+N7+N8+N4 #= Const, fd_labeling(Numbers), write(Numbers), nl, fail.
Lägg märke till den strukturella likheten med mitt första, stendumma, försök; först tala om hur lösningen bör se ut, sedan villkoren. Och för den som är bekant med Sidney Harris’ klassiska teckning, det är i fd_labeling miraklet sker — där används den givna informationen på något intelligent sätt; min nya dator behöver nu bara en kvarts sekund på sig för att lista alla lösningar.
Jag hoppas detta exempel visar att det fortfarande är viktigt att veta vad man pysslar med — att skriva in data och regler/relationer, för att sedan låta maskinen överta alla beräkningar är än så länge bara en dröm.
![]()
Låt mig avsluta med att begå det brott jag tidigare yrkade på dödstraff för, men i en form som förvisso inte meriterar en så hård påföljd. Jag har nämligen sedan någon månad tillbaka övergått till en av Prologs efterföljare, Picat, som tagit med sig många av de goda sidorna i Prolog, och samtidigt rättat till en del av missarna. Så här försöker man fixa till fibonacci-problemet (från boken »Constraint Solving and Planning with Picat», som kan laddas ner som en PDF-fil från sajten i länken ovan).
table fib(1) = 1. fib(2) = 1. fib(N) = F, N > 2 => F = fib(N-1)+fib(N-2).
Det som räddar författarna (och mig) från galgen är ordet »table»; detta anger att resultat ska cachas, vilket enligt författarna förvandlar beräkningstiden från exponentiell till linjär. Jag har inte undersökt detta närmare, men det låter underligt i mina öron. Om resultatet cachas fullt ut, borde beräkningstiden vara konstant om resultatet fanns i cachen, linjärt om det måste beräknas. Men hur som helst kommer man inte ifrån att rekursion kräver utrymme på stacken, så även om rekursionen i det här fallet är acceptabel, så är det inte det bästa sättet att utföra beräkningen. SDS.
Fotnoter:
- Här antar jag alltså att en sådan existerar, vilket naturligtvis är mer baserat på en önskedröm än något slags verklighetsunderlag. [↩]
- Det händer dock att verkligheten tränger sig på och genererar ett avbrott, och en gång har till och med en av dem gjort en miss och tvingats ge upp (för att sedan i ett tillägg förklara sin miss och korrigera den). [↩]
- Egentligen räcker det ju att säga ett ferssteg ifrån varandra, eftersom kungens raka stegmöjlighet redan är förbjuden med standardsudokuregler. [↩]
- eller ett vesir-steg från varandra, om vi ska fortsätta med (fantasi)schackpjäs-terminologin [↩]
- Inte första gången, och antagligen inte sista, där den stupida envishet jag understundom kan utveckla kan misstolkas som ett utslag av intelligens. [↩]
- Eller, för att vara mer exakt, Calc, Libreoffice’ klon av Excel. [↩]
- Det är nu inte hela sanningen, eftersom min boksamling även innehåller en bok om LISP, men jag vill ju inte framstå som en person som gör saker lite slumpartat, så därför måste jag uppfinna ett skäl för mitt handlande. [↩]
- Detta senare försök att förändra utseendet kan dock verka misstänkt på eventuella kvinnliga fibonaccirekursionister, så dessa bör nog försöka andra förklädnader. [↩]
- Jag är inte säker på det exakta antalet, men mitt undermedvetna propsar på att skicka fram detta tal. Det är i alla fall inte helt taget ur luften. [↩]
- Och med ett »riktigt programmeringsspråk» avses naturligtvis Fortran. [↩]
- Det betyder visserligen att jag inte skulle vara berättigad att använda rekursion än, så jag har för mitt samvetes skull lagt till att tre års Pascal-programmering må i särskilt behjärtansvärda fall få ersätta ett års »riktig» programmering. [↩]
- Så Det Så [↩]
- Och Hör Sedan [↩]
- Nej, jag har inte stavat fel; jag kunde bara inte bestämma mig för om skillnaden var makaber eller remarkabel, så jag skapade ett nytt ord. [↩]